You can’t outrun a data mess
Anyone who’s worked on AI initiatives knows this truth: slow progress on data quality keeps most Data Leaders awake at night. These leaders live and breathe data governance and quality—they’ve seen the consequences of bad data firsthand and are eager to fix it. Engaging with these champions early in an AI journey is almost a rite of passage; they become your essential allies in building robust foundations that AI truly needs.
But why does fixing messy data matter?
The nagging feeling that people on both sides of the table continue to have, as we scale AI adoption across the Enterprise is = the correlation between data quality metrics and AI ROI is fundamental and deep. High-quality data is the bedrock upon which AI's potential for delivering measurable business value rests. And achieving high-quality, trusted data is still a distant goal for many enterprises.
Let’s take a simple, 10,000 ft view of our commonly measured Data Quality metrics, and their impact on AI use cases.
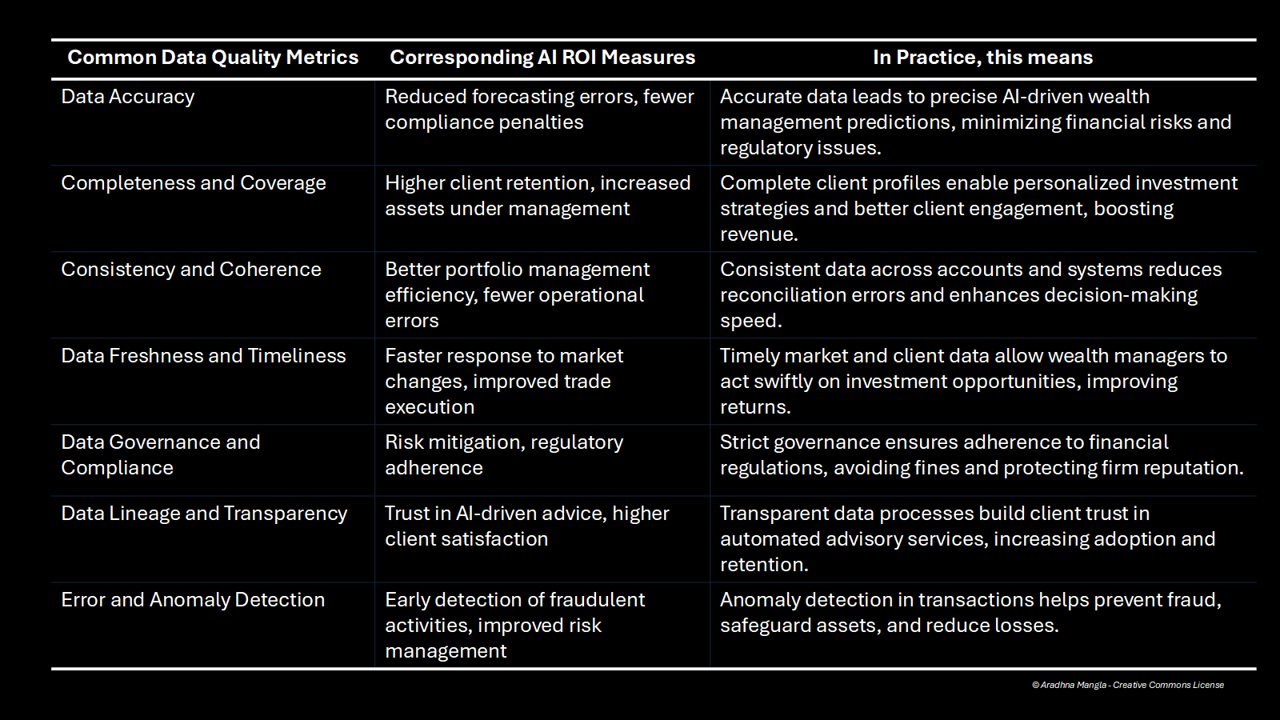
Simple is key to democratizing the idea, and engaging stakeholders IMO
So what does bad data quality mean when we ‘apply AI’?
Before we proceed further, we must establish some facts: we cannot ‘govern’ 100% of enterprise data - there simply isn’t an ROI. However, in today’s risk environment, we should at least be able to know where the organizations’ data is, where it comes from, and if it is authorized for use.
So yes, there will always be some ungoverned, messy data lying around. Just hope it’s not the stuff going into your credit decision model!
Since there isn’t a perfect/one way to measure the aggregate impact of data quality - here’s an idea open to discussion:
Why don’t we do some napkin math and observe the interaction between AI models, your internal and external data sources, columns of data to maintain, and impacts on the Data Steward - who is still 100% human, and working with a variety of Data Management Tools, Emails, Meetings, and Excel Templates?
“(Number of AI Models) × (Data Sources per Model) × (Data Points per Source) × (Data Quality Remediations per Data Point) = Total Data Quality Tasks”
What does this mean in reality?
There are about 2 million models out there in the world. They range from public to private, branded, big names to unsecure, shadily out there.
If we take a ballpark range of model usage by use case/enterprise size (this might serve as a good class table)
Large enterprise: 500–2,000 models
Medium enterprise: 100–500 models
Small enterprise: under 100 models
Where does this leave us - in a conservative scenario of a .02% error rate?
“1,000 AI models × 10 data sources per model × 100,000 data points per source × 0.0002 error rate = 2,000,000 data quality incidents to monitor and remediate”
Even if only 0.02% of your data has issues, that’s potentially hundreds of thousands of incidents daily. Can your teams triage, fix, and optimize fast enough? Without solid data quality foundations, AI projects risk becoming bottlenecks, eroding trust, and wasting investment dollars.
Attempting to “outrun” a data mess is a myth - experienced Data Leaders know that strong, resilient data foundations must precede any ambitious AI project. Investing in data governance, rigorous validation, timely updates, and unified data standards is critical for preparing “AI-ready” data sets that enable successful business outcomes.